For CoK 2023 I ran a combat simulation of all the non-individual units (here) to see how they’d compare head-to-head in hypothetical match-ups. I updated that analysis for CoK 2024. To save you some time, I’ll walk through the methodology.
This study was conducted using a custom-built Python combat simulator, designed to analyze unit effectiveness in Kings of War through 1.25 million combat simulations. The simulator included specific special rules to closely mimic actual gameplay dynamics. Key features of the simulation:
- Initiative and Randomization: Generally, faster units were programmed to strike first. However, to reflect the unpredictability of real-life combat, a randomizing factor was introduced, altering this sequence in some battles.
- Terrain Effects: In approximately 30% of the simulations, battles were set in varied terrain to account for the environmental impacts often encountered during gameplay.
These aspects were carefully integrated to ensure a balanced and realistic representation of combat scenarios in Kings of War.
Methodology
- Simulations: 250,000 matchups, each with 5 battles, totaling 1.25 million combats.
- Special Rules Included: Blast, Brutal, Cloak of Death, Crushing Strength, Dread, Elite, Fury, Headstrong, Iron Resolve, Lifeleech, Pathfinder, Phalanx, Piercing, Radiance of Life, Regeneration, Shattering, Stealthy, Strider, Thunderous Charge, Vicious.
Elo Rating System
The Elo rating system, used in this study, calculates the relative skill levels of units in Kings of War based on their performance in simulated combat.
- Initial Rating: Each unit began with a set baseline Elo rating. This standard starting point is common in Elo systems and ensures all units start from an equal footing.
- Rating Adjustments After Combat: After each combat, the Elo ratings were updated. The adjustment is made based on whether the unit won, lost, or drew, and how unexpected the outcome was, given the difference in ratings between the competing units. The process involves:
- Adding points to a unit’s rating if they win, especially against a higher-rated opponent.
- Losing points in the case of a defeat, particularly when losing to a lower-rated opponent.
- The amount of adjustment depends on the difference in ratings and the expected outcome of the match. A surprise victory or defeat leads to a more significant change in rating.
- Expectation Calculation: The system calculates the expected outcome of a match based on the current ratings of the two units. Units with higher ratings are expected to win more often against lower-rated opponents. If a high-rated unit wins against a lower-rated unit, the rating change is smaller, and vice versa.
- Effectiveness Determination: Once I had the Elo rating, I evaluated the ratio between cost and Elo to determine what units are over or undercosted.
This Elo system allows for a dynamic and responsive evaluation of unit effectiveness, reflecting not just the strength of the units but also the context of their victories and losses.
Analyzing Unit Size Variability
There’s a lot to unpack from the simulation, but I’ll start by looking at unit sizes and how performance differs. First, a box plot:
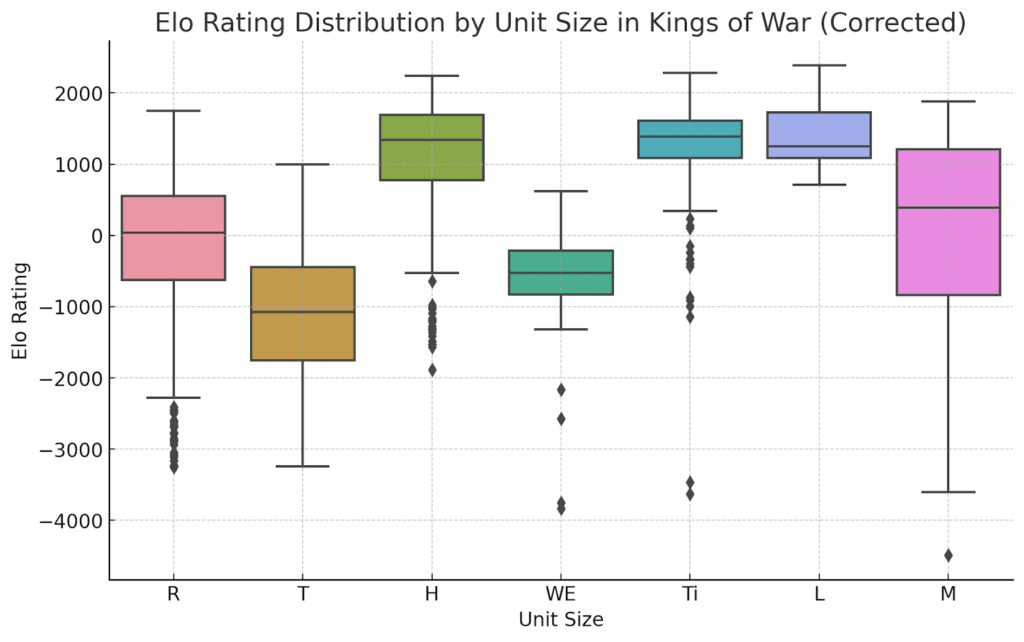
Standard Deviation Insights: The standard deviation of Elo ratings across different unit sizes (Horde, Legion, Monster, Regiment, Titan, Troop, War Engine) highlights the variability in performance within each category. Specifically,
- Monster: 1426
- Regiment: 994
- Titan: 890
- Troop: 871
- Horde: 794
- War Engine: 784
- Legion: 460
Monsters show by far the most deviation, followed by regiments and to a lesser extent titans and troops. Legions had the smallest variation. The box plot visualizes the spread of Elo ratings across unit sizes. The wider the distribution, the more varied the performance of units within that category.
What does this mean, and why are monsters so swingy? Two thoughts: first, I suspect monsters have a greater percentage of special rules than other unit types, and if those rules aren’t captured in the simulation, they’ll make some monsters appear artificially worse at what they’re doing. Second, monsters, with a 50mm square base, have much of their value showing up in how you use them as opposed to their straight stat line. In a skiller player’s hands, monsters probably add greater value than other equally-costed units (or at least have the potential to have bargain points finds). On the other hands, legions are pretty straightforward and have reduced variation, which additionally reduces the chances either of buying a lemon or getting a unit that outperforms its points.
How Keywords Impact Performance
Next, I wanted to take a look at what impact the keywords have on the Elo ratings. My deep dive into the dataset, encompassing various units and their attributes, revealed fascinating insights. First, an ANOVA (Analysis of Variance) test was employed to discern the influence of specific keywords on units’ Elo ratings. Surprising no one, the top keywords with the greatest impact were Crushing Strength, Strider, and Brutal. Units equipped with Crushing Strength showed a profound impact on their performance, a notion supported by an astonishingly low p-value of 1.96×10−56 in the ANOVA analysis. Similarly, Strider and Brutal also correlated strongly with higher Elo ratings.
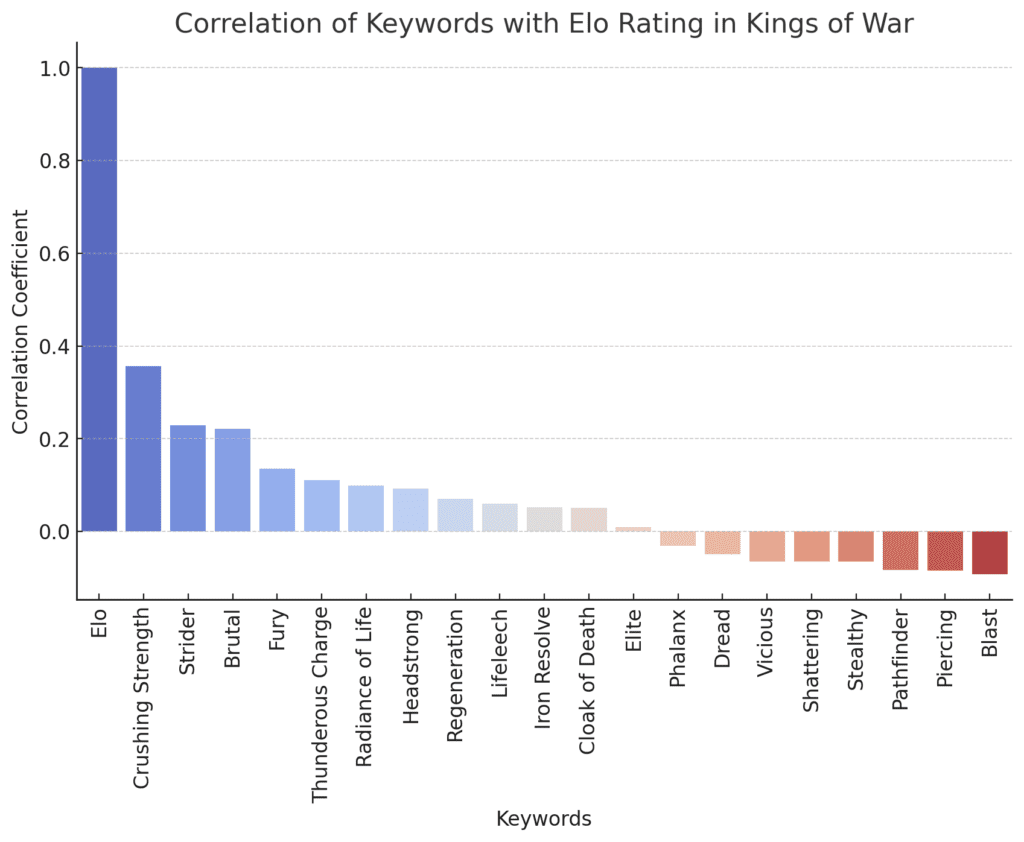
Complementing the ANOVA findings, a correlation analysis offered additional dimensions of understanding. It highlighted that while keywords like “Crushing Strength” and “Strider” positively correlated with Elo ratings, others such as “Blast” and “Piercing” showed a negative correlation. In general, many shooting-related keywords were negatively correlated with Elo. This suggests that in a 1:1 match-up, shooting units are at a disadvantage. Their strength lies in the ability to focus fire and virtually “gang up” on units, avoiding single combat, as a way to level the playing field.
I’ll have additional analysis to follow, but please comment on anything specific you’d like to see from the new CoK 2024 simulations.

